Tutorial on Using Keras for digits recognition
Once you installed Keras and made sure it works, let’s do something.
Typical “Hello, World!” example for neural networks is recognizing the handwritten digits. There is a famous MNIST dataset, containing grayscale images of the handwritten digits from 0 to 9.
The images are 28x28 pixels size:
Neural networks may sound complicated, but with Keras it is possible to create neural network, train it, and estimate the accuracy of the predictions on unseen data with only 10-20 lines of the code.
Here is the Jupyter notebook for the tutorial, please fell free to download and play with it.
To make things more fun, I use the dataset provided by Kaggle training competition Digit Recognizer. It uses the MNIST dataset (download it), and as a side effect, we will be able to score the result on the Kaggle Leaderboard of the competition.
Creating the model
For this tutorial, I created a very simple net with one hidden fully dense layer with 32 nodes.
The input layer has 784 nodes - a node for every pixel in the image.
Each of the 32 nodes in the hidden layer connected to each of the 784 input nodes.
And we have 10 nodes output layer with standard softmax activation.
The whole code for creating this neural network:
model = Sequential([
Dense(32, input_dim=784),
Activation('relu'),
Dense(10),
Activation('softmax')
])
# Multi-class classification problem
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
This simple net requires totally (784 + 1)*(32) + (32 + 1)*10 = 25450 parameters to fit.
Not a small number for such a simple NN! And we have only 42000 digits in the training set.
So as you can imagine, we definitely should look out for overfitting here.
Fitting the model
The code for fitting the model (training):
history=model.fit(train_images.values, train_labels.values, validation_split = 0.05,
nb_epoch=25, batch_size=64)
Estimating accuracy
Parameters for model.fit() mean that every [epoch][wiki-epoch] we will use 5% of the training data to validate
accuracy (i.e. estimate accuracy of the model for unseen data).
As we see from the following picture overfitting happens already on 8-10 epoch.
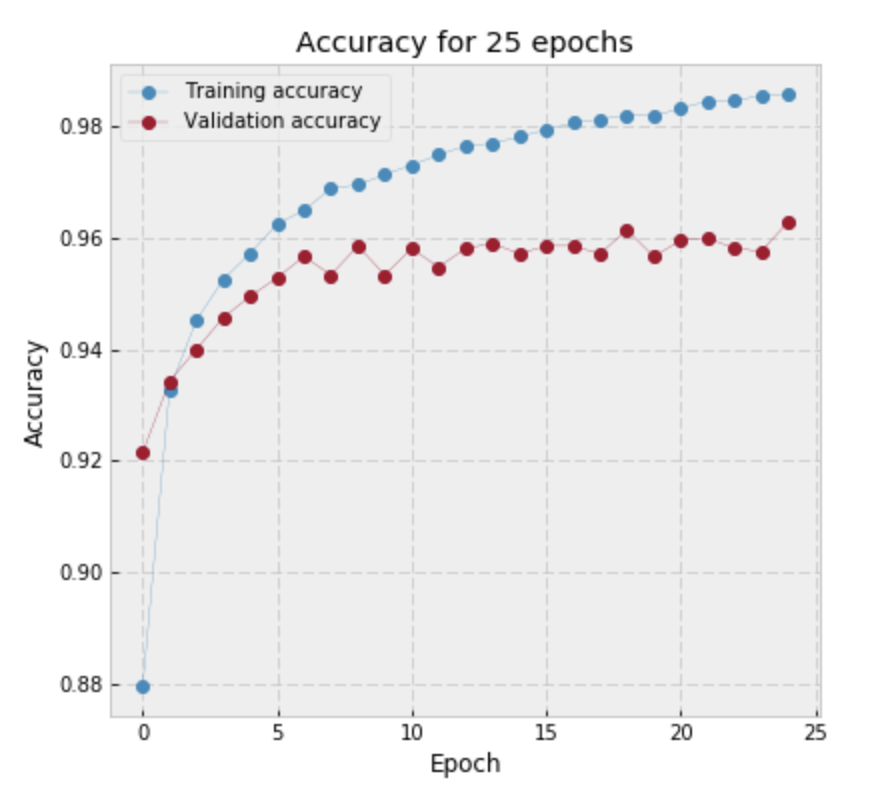
Basically what we did here was tuning hyper-parameter ‘number of epochs’ using validation.
Submitting to the Kaggle
To create submission file, I do the model fitting on the whole training dataset with
nb_epoch = 10.
For this simple NN I’ve got 0.96257 score. For this competition, the score is defined
as the categorization accuracy of the predictions (the percentage of images you get correct).
So, 96% accuracy for unseen test data is good, right?
But nowadays, this result isn’t considered as good. The best you can get using only one hidden layer NN,
for now, is around 99.3% accuracy.
But please don’t use Kaggle leaderboard as a target for the accuracy.
Apparently, some people with 100% accuracy
just cheated somehow (i.e. overfitted on the testing dataset somehow).
Can we do better?
The next steps from here would be to try
hyperparameters tuning.
Please feel free to do it by yourself, here is the source of the code for this post.